
Microservices architectures are the dominant force in today’s software engineering realm. This infrastructure approach—despite its multiple benefits—has created quite a tangled management web. IBM has corroborated this, sharing that applications consist of “dozens, hundreds or even thousands of distinct, independently deployable and updatable services.” Apart from maintaining service reliability, administrators must effectively govern permissions for hundreds and even thousands of users.
This means that your backends must both authenticate and authorize users before they can access specific services. It’s critical that users are in fact logging in as themselves and have the required clearance to perform certain actions afterward. Determining permissions, role-based access control (RBAC), and other controls is tricky enough. Additionally, the granularity with which you manage service-related permissions is variable.
Devising clear user permissions strategies is critical for maintaining security, service availability, and microservices scalability over time. You cannot safeguard your API endpoints with a swinging door. Controlling what users see and do during a session is fundamental to application management.
Assessment Criteria
This article introduces some useful user permissions strategies when using microservices and breaks them down. The goal is to help you understand which strategy may work best for your organization’s services. We’ll evaluate each permissions strategy based on the following:
- Ease of use: How user-friendly is the approach, and how simple to use are its fundamental functions day in, day out?
- Maintainability: How easily and quickly can administrators make changes to permissions, groups, and structures in the wake of needed scalability or change?
- Stability: How resilient is the solution against unintended failure, and how effectively might the APIs or mechanisms behind it function long term?
These criteria form a strong baseline for measuring strategic effectiveness.
Permissions Strategies Introduction
There are two principal pathways you can take while managing your permissions, and each comes with its own nuance. For starters, you can choose to manage all permissions on your own—in other words, without deferring to a centralized, third-party tool. This is otherwise known as the granular approach. Teams adopting this method typically desire unfettered control over their deployments.
Without diving too deeply into the strategy (more later), there are many sub-approaches that you can pick from, depending on your users, application-to-application relationships, session design, server arrangement, and API dependence.
Conversely, there’s the centralized service approach. This often relies on external tooling and integration of third-party services that maintain some level of backend access to your permissions. You’re therefore able to manage permissions and roles using a unified interface (including the CLI). There’s typically less reliance on changing actual services code; your focus will instead be on configurations.
Each strategy has its advantages and disadvantages. Use cases also vary depending on your infrastructure. That being said, let’s dive in.
Strategy 1: Managing Your Own Permissions
A quick disclaimer: self-managing your permissions can be a laborious process. However, the extra work involved is a trade-off for exerting granular control over permissions on a service-specific basis. Since you’ll be shouldering much of the setup burden, it’s worth knowing the challenges that accompany a self-managed microservices architecture.
Remember that user permissions, first off, are tied closely to authentication and authorization. Your permissions settings directly influence the course of a user session from login to logout. When scaling these behaviors to multiple user accounts, some notable obstacles become apparent:
- An application leverages many microservices processes in unison, and thus, it’s necessary to silo these services on the permissions front. User access requests to each service must be handled separately on the backend.
- You must reconcile the relationship between service-level authentication and authorization logic with global logic; while code reuse is possible, it creates dependencies that ultimately hamper systemic flexibility.
- Microservices must handle their own business logic and adhere to single responsibility amid the overarching presence of global permissions logic.
- HTTP’s stateless design is great for server and node load balancing, but the loopholes needed to make it compatible with stateful login sessions render services less scalable.
- Authentication and authorization are inherently more complex due to diverse interactions powering the app functionality.
The premise behind any self-governed permissions strategy is to creatively sidestep these limitations. There are multiple ways of doing this, which we’ll now explore.
Stateless Session Management
It’s often preferable that microservices remain stateless. Multiple containers compete for a shared pool of resources, especially when services experience heavy user activity. These peak usage periods incur large memory requirements; accordingly, stateless requests require much less memory overhead. These new transactions are lightweight and agile. Additionally, servers can process numerous requests in parallel, boosting stability and performance. This is important when multiple users are logging in and accessing resources simultaneously. These show up the same for all users at once.
That said, it’s possible to marry the benefits of the stateless approach with sessions in three ways.
The first is by using something called a sticky session, where the server handling initial requests from a user is pinged for any subsequent requests. Load balancers are critical to allowing this yet only allow horizontal cluster expansion. This instance of adding machines (instead of expanding upward by upgrading current machines) is preferable, however, because it allows hundreds or thousands of concurrent user sessions. Naturally, these sessions require authentication and repeated authorizations based on their behaviors. Just remember that forced server swaps will dump user session data in this scenario—requiring new logins and hits to the authorization server.
The second is session replication, in which user session data is saved and synced across the network. Any changes in user data are automatically pushed to all machines. This method of user handling, therefore, consumes more resources, typically in the form of bandwidth. There’s good consistency here; the server doesn’t just forget the user’s privileges or forget an account’s backend associations. Unfortunately, scalability is more limited.
The third is centralized session storage, which places user credentials and associated data in a shared location. Login statuses remain opaque, meaning credentials aren’t interpreted by the server in plain text. This is great for security. While scalable, this approach requires protection mechanisms for shared storage.
Client Tokens
Tokens help overcome the stateless-stateful clash between microservices and their servers. Instead of storing user sessions on the servers themselves, tokens serve as storage vessels for user identity details. This is seen most often in web-based services that utilize cookies. Users retain their tokens and session information on-device.
All user requests to the server leverage this token to confirm identities, then determine how privileges align with each user. This determines what content users can view, interact with, and even modify. Opaque tokens are specialized tokens used in some situations; these are proprietary, in the case of OAuth, and inaccessible, while pointing to information persistently stored on the server. OAuth is a popular authentication provider and offers both Management API and custom API access tokens.
Additionally, the JSON Web Token (JWT) is a popular token format that’s standardized and built upon three elements. The header contains a type and hash algorithm (as tokens must be encrypted). The payload contains a user ID, username, and expiration date. It can also contain roles. Finally, the signature verifies the token identity to the client and provides validation. Tokens are often refreshed after short periods to preserve security in case attackers steal them.
The tokenization process is as follows:
- An API request is made to initialize login
- The server creates a token
- The token returns to the client’s browser where it’s stored
- The user sends the token via header to the server when actions are performed
- The signatures are verified, and user information is summoned
- An appropriate response is sent to the client
It’s also possible to pair tokenization with API gateways. Instead of requests directly hitting the server, an intermediary gateway vets the action and passes it along. Microservices aren’t exposed to the user, and the gateway can revoke tokens—either when a problem is detected or when the user signs off. Authorization tokens are hidden from the client and, thus, cannot be decrypted so easily.
Single Sign-On
Single sign-on (SSO) is perhaps the most streamlined method for access management, as it allows one user login verification (the authentication step) to authenticate that same user across a host of bundled services. It’s now common for one application to host numerous services within its functional boundaries. Signing into everything, service by service, would be extremely tedious for the user. Access to all services is routed through a centralized authentication service. While convenient in many respects, this approach can be prone to failures or network traffic spikes.
Mutualized Authentication
It’s common for microservices to communicate with one another while services are live. Accordingly, interconnected microservices share plenty of traffic as users go about their business. A two-way SSL connection allows mutual authentication since authentication certificates unique to each service are exchanged via TLS. The ever-changing nature of application instances throws a wrench into this certification process, but there’s some good news: a private certificate center can help determine how certificates are issued, revoked, and updated for all applicable services.
Words of Caution
The common bugaboo among all these options is the ease of use. Each has a certain give and take, and requires some degree of manual setup in order to be successful. While built-in automation can indirectly or directly simplify the process of permissions handling, specific expertise is needed within your team. Sound execution of these strategies requires professionals well-versed in APIs, security, and microservices architecture. Those light on experience are more prone to making mistakes, and those mistakes can undermine permissions handling.
Mechanisms, like RBAC and attribute-based access control (ABAC), are also living, breathing philosophies that require constant maintenance over a service’s lifecycle. There are many places where self-managed authentication and authorization can go wrong. Implementing this in an invisible fashion (as far as the user is concerned) is also central to systemic security. Poorly coded solutions can offer too much information on your backend’s permissions structure.
Can open-source resources ease the development pain? While that answer is yes in many circumstances, the fact remains that successful integration is challenging. Documentation is hit or miss, cross-language logic sharing is dubious, and coding efforts can be vast.
Authorizing Users After Authentication
Once your services determine who you (or your users) are, they then determine what one can actually do within an application. It’s possible to do this for each service individually, though this route takes some time and introduces potential hiccups.
While good for security and fine-grained control, this requires that you rewrite the security logic for all microservices. That leads to bloat via duplication. It also links each service to external authorization data that it doesn’t own. Finally, these piecemeal designs are trickier to monitor as services scale.
Teams often employ a form of shared authentication library attached to each service to circumvent these core issues. They may also establish global services that tie authorization and authentication together—usually through an authorization database. Unfortunately, this latter approach processes individual user roles using a global service. These checks bring security concerns and add latency.
Isn’t there a better way to handle authorization? Many argue that centralized services are both effective and low-maintenance for teams overseeing them. This can avoid the strong coupling problem experienced within traditional API gateways and single endpoints. Third-party services now exist that markedly streamline these steps.
Strategy 2: Using a Centralized Service
While individual management can be complicated, the centralized approach can grant you much-needed simplicity. This strategy uses a central microservice that is deployed among your existing applications. This is often in the form of a supplemental container.
Certain third-party services, like Cerbos, can even operate as a sidecar—which is loosely coupled to its associated applications while doing permissions-based legwork in lockstep. These sidecars are useful since they extend upon the capabilities of existing services.
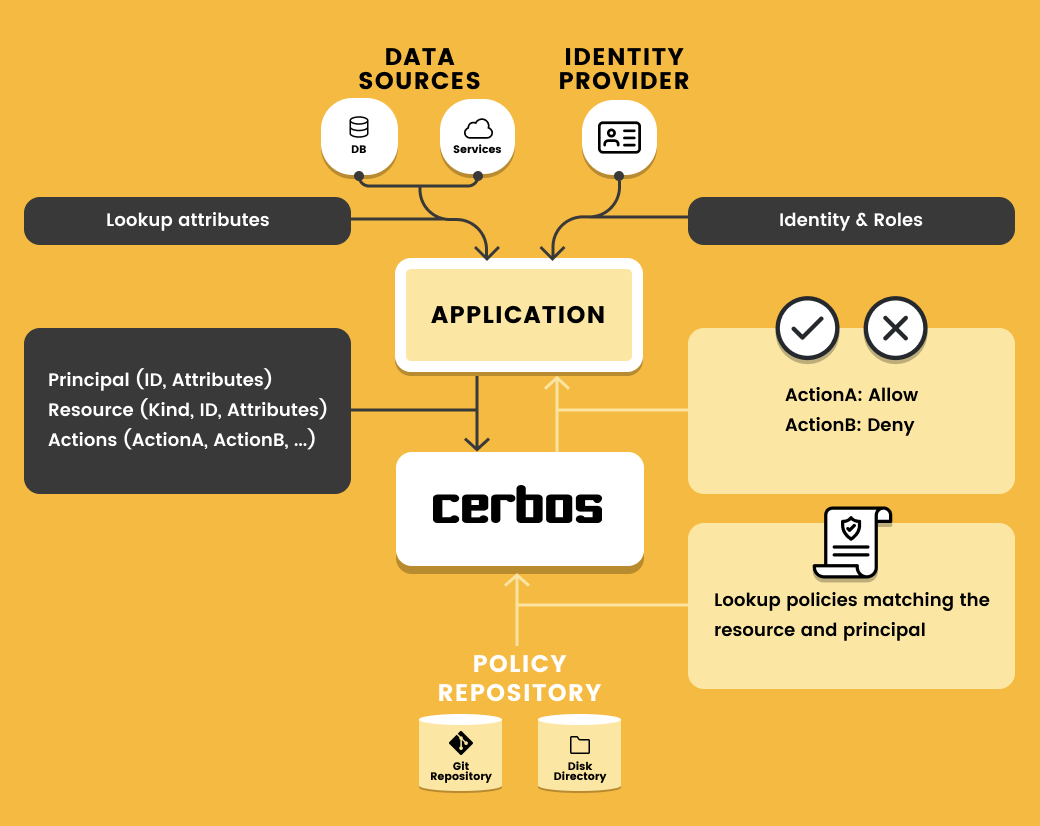
All services making authorization and authentication requests route them through that dedicated permissions microservice. A response is sent back to the client, ultimately determining whether their request was successful. This centralized piece enforces all permissions-based decisions. However, a problem can occur when running multiple nodes together and one of those nodes is partitioned.
Say one node is effectively separated from other system nodes. In a centralized setup, this node cannot receive any permissions decisions from the external service. It can fail closed—rejecting all authentication requests—or fail open. The latter is extremely problematic, as all authentication requests are approved. Failing closed can cause a ripple effect in which all clients of the partitioned service have their requests denied.
When we consider something like Cerbos, the picture thankfully becomes a little clearer. The solution is friendly to non-developers since it requires little knowledge of access rules or languages. Permissions logic changes are automatically pushed everywhere to every corner of your infrastructure, saving time and headache. The solution has no dependencies and remains contained to the local network. Centralized tools like these can even determine roles while facilitating GitOps.
Centralized services are great for keeping things simple. They act as a single source of truth for microservices permissions rules and run without complicating an already intricate system. Modern derivatives are designed for containerized environments and utilize popular API protocols to operate effectively.
Small teams without deep knowledge of permissions security will benefit heavily from using a centralized service. While configurations remain robust, there’s much less work to be done when enforcing authentication and authorization. If you’re using multiple frameworks or languages throughout your deployments, a centralized solution brings the agnosticism you need for rapid implementation. They even incorporate some form of testing—which is useful, as permissions and microservices evolve over time.
Maintenance costs are inherently lowered as well. Because the central service can push changes to all services, you don’t have to spend development resources for individually updating each service. Organizations running a high volume of services may find solace in this fact.
Conclusion
In the battle of self-management vs centralization, picking a winner isn’t so black and white. A team’s comfort level with its infrastructure, certain technologies, and budget will determine the appropriate course of action. While even popular setups, like OAuth + JWT, are secure and proven, they’re not foolproof. A centralized service can check many functional boxes for teams without being too finicky or intrusive. Devising a strong microservice permissions strategy is often the hardest security step that companies can take. Hence, centralization can make that easier for teams not married to common stateless methodologies.
Check out our core guide on microservice authorization.
Tagged in





